
Introducción
Una de las diferencias importantes cuando nos ponemos a comparar una base de datos documental vs relacional es que podemos tener documentos ricos, es decir, que tengan campos que sean objetos o arrays, o incluso arrays de objetos y anidar estos. Esto choca mucho con la aproximación clásica relacional, en la que lo que tenemos son datos tabulares (un campo debe tener un tipo simple) y que nos obliga a acabar con esquemas de base datos grandes y consultas complejas para modelar problemas relativamente sencillos.
Usando la aproximación de embeber documentos en MongoDB podemos obtener los siguientes beneficios:
Simplificamos las consultas.
Mejoramos el rendimiento.
Y a veces incluso las dos anteriores de una tacada :).
¿Quiere esto decir que siempre tenemos que embeber documentos? La respuesta es NO, en este post vamos a dar una serie de pautas que nos podrán servir de ayuda cuando estemos modelando y necesitemos decidir si embeber una colección o no.
TL;DR;
MongoDB nos da la opción de que un documento pueda contener a otros, esto hace que nuestras consultas se puedan simplificar y en algunos casos obtener un rendimiento bastante bueno, peeerooo si no sabemos como aplicar esto, nuestro modelado se puede ir al traste.
¿Cómo saber cuando embeber o mantener colecciones separadas? En el mundo documental, no existen unas reglas tan claras como cuando modelamos otros concerns en Bases de Datos Relacionales, aquí van unas pautas:
Debemos tener muy claro que es el Working Set: es decir la caché en memoria de MongoDB, si la llenamos de datos que no se suelen consumir a menudo, haremos que Mongo tenga que ir con más frecuencia a disco duro a traerse información y el rendimiento que obtendremos será peor.
Si queremos almacenar un array de subdocumentos y pueden haber miles de entradas, tenemos que tener en cuenta cual es el tamaño máximo de un documento de Mongo (16Mb), y aunque no lo supere, analizar si es óptimo mantener toda esa información en el Working Set que vimos en el apartado anterior.
Existe una aproximación intermedia: el subset pattern, en el que sólo guardamos de la lista de subdocumentos una copia de los campos que nos interesan (en el caso de que sea un objeto) o los n primeros / los más relevantes (en caso de que estemos tratando con un array), el documento o colección completa la almacenamos en otra colección.
Viendo el ejemplo anterior, te habrás dado cuenta de que en Mongo hay veces que es aconsejable duplicar datos, esto está bien si el número de lecturas es muy superior al de escrituras, ya que si un día toca actualizar, tenemos que escribir en varios sitios: puede ser costoso y también es más fácil que cometamos errores.
¿Te ha parecido interesante este resumen? Vamos a bajarnos a detalle :)
Documentos y colecciones vs registros y tablas
Si vienes del mundo relacional, te puedes sentir un poco fuera de lugar cuando nos liamos a hablar de términos tales como documentos o colecciones, vamos a hacer una traducción a conceptos que ya conoces:
Documento: vendría a ser como un registro de una tabla de base de datos, con la diferencia que aquí los campos pueden ser compuestos, además de tipos planos, soporta objetos, arrays...
Colección: lo podemos asimilar al concepto de tabla de una relacional, en este caso una colección esta compuesta por documentos.
¿Qué es eso de embeber?
Cuando hablamos de embeber (palabro incorrecto en Español, viene del inglés embed su traducción es complicada: empotrar, incrustar, integrar...), nos referimos a que un documento puede contener a otros, por ejemplo, tenemos un pedido: este pedido se compone de una cabecera y una lista de líneas de pedido, ¿Que haríamos en una base de datos relacional? Crearíamos una tabla con la cabecera del pedido, otra con la línea de pedido y una relación de uno a muchos que iría de la primera a la segunda:

Fíjate que aquí tenemos que tirar un JOIN en nuestra consulta para sacar los datos que necesitamos(\*).
SELECT cp.id, cp.nombre, cp.direccion, cp.codigoPostal, cp.ciudad, lp.producto_id, lp.cantidad, lp.precio
FROM cabecera_pedido cp
INNER JOIN linea_detalle_pedido ldp ON cp.id = ldp.id_cabecera_pedido
WHERE cp.id = 1
(*) También podríamos ver de tirar dos consultas una para la cabecera y otra para el detalle.
En MongoDB, podemos hacer lo mismo, y ahí es donde empiezan los problemas, si intentamos modelar documental aplicando sólo los principios de bases de datos relacionales, lo más seguro es que acabemos con un rendimiento pésimo, si queremos aprovechar la potencia del motor, debemos tener en cuenta que esta base de datos no es buena "haciendo joins", aquí es donde podemos plantearnos lo siguiente:
Siempre que cargue un pedido, lo normal es que cargue la cabecera y el detalle del mismo, así que puedo modelarlo todo en una colección, de esta manera, me lo puedo traer todo en una tacada, y no tengo que hacer un JOIN.
Veamos como modelar esto en Mongo:

¿Y como sería la consulta para cargar el pedido con id 1?
db.pedido.find({ id: 1 });Si te fijas estamos trayéndonos todo en una sola consulta bien simple(*).
(*) Más adelante en este post le daremos una vuelta de tuerca a este ejemplo, y veremos que depende mucho de la naturaleza de tu aplicación elegir una aproximación u otra.
Entendiendo el working set
MongoDB tiene precargado en memoria los documentos que más se usan, evitando así tener que ir a disco duro para leerlos (leer de disco duro es más lento que leer de memoria), a esta _caché_ en memoria le llamamos Working Set.
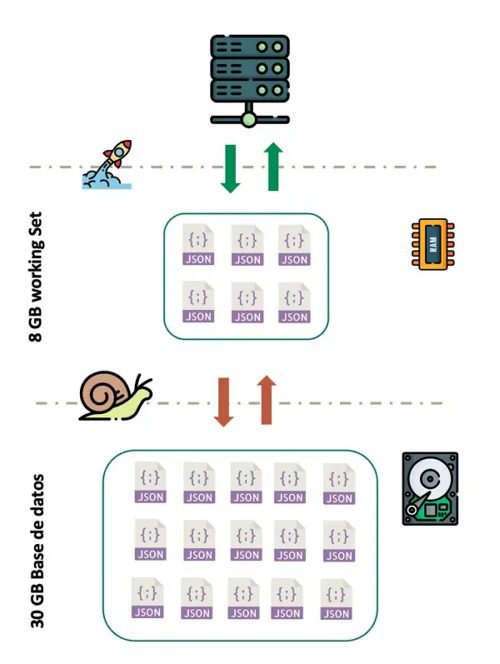
Es decir, nos interesa que la información que más se usa se almacene en este área.
Cuando leemos un documento, este se carga al completo en el Working Set, ¿Qué quiere decir esto? Que si ese documento contiene un montón de información que no se suele usar en la aplicación, estamos llenando el Working Set de basura, y el motor de Mongo tendrá que ir más a menudo a disco duro para traerse la información que necesite.
Es decir, tenemos que evitar que documentos que se usan a menudo, tengan información adicional que no sea relevante, en ese caso es mejor extraer esa información a otra colección y mantener así un Working Set óptimo.
¿Oye y como se si mi cluster de MongoDb tiene el working set a tope?
Una opcion es tirar de terminal y ver cuantos Page Fault tienes, ejecutando db.serverStatus
db.serverStatus().extra_info
Esto te indica cuantos estás teniendo (campo page_faults):
{
"note" : "fields vary by platform",
"user_time_us" : NumberLong(2844130),
"system_time_us" : NumberLong(2059593),
"maximum_resident_set_kb" : NumberLong(111176),
"input_blocks" : NumberLong(149136),
"output_blocks" : NumberLong(0),
"page_reclaims" : NumberLong(17223),
"page_faults" : NumberLong(861),
"voluntary_context_switches" : NumberLong(17943),
"involuntary_context_switches" : NumberLong(1105)
}O si estás tirando con la cloud de MongoDB (Atlas), te puedes ir al tab de métricas, y abajo del todo elegir el chart de _Page Faults_ y podrás verlo en formato gráfica:

Si quieres ir a grano fino también podrías mirar de utilizar otras herramientas tales cómo Grafana.
¿Y esto del Page Fault que me está indicando? que es un error de página, es decir, que el motor de Mongo no ha podido encontrar el documento en el Working Set, y ha tenido que ir a disco duro a buscarlo, y esto es leeeeento ¿Cómo lo puedo evitar?
Aplicando cambios a nivel de modelado (no tengo que invertir en Hardware).
Escalando en vertical (más memoria RAM ¡Esto es la guerra!... gastamos dinero y tenemos un límite físico).
Escalando en horizontal, utilizando técnicas como sharding (más servidores, más complejidad y posibles problemas, ...gastamos dinero y vamos a tener más dolores de cabeza).
Así que el primer paso evidente es irnos al modelado 😄.
Para para... me estoy liando 🤨 ¿Antes me estabas diciendo que anidara documentos, ahora me dices que saque fuera la información? ¿En que quedamos? Vamos a ir desgranando esta contradicción en los siguientes puntos.
Todo o nada
Un tema importante es que un documento se carga en la caché del working set al completo, por mucho que proyectemos o lo que sea, documento tocado, documento completo que se almacena (no hay cargas parciales).
Tamaño máximo de un documento
Sigamos con límites físicos, ... el motor de MongoDB tiene un limite de 16Mb por documento, muy bien, esta cantidad es una burrada, ¿De verdad que alguien puede llegar a meter más de 16Mb en un documento? Puuuuede... veamos un ejemplo:
Queremos almacenar la información de un producto y las reseñas de los usuarios, podemos plantearnos embeber las reseñas en un array dentro del documento de la ficha del producto ¿Qué puede ir mal? Bueno, si estamos hablando de un Amazon, puede que alguna entrada muy popular y veterana pudiera tener más de 100.000 reseñas (💣 BOOOOM !).
¿Y que me dices de twitter? Queremos almacenar el array de personas que siguen a una cuenta... Barack Obama tiene millones de seguidores
Así que, cuidado con esto, cuando embebas un array, plantéate cual va a ser el número mínimo, medio, y máximo de subdocumentos que va contener (ese máximo, aunque sólo se de en un caso, te puede aguar la fiesta), ..Vale, esto me limita mucho ¿Qué hago entonces? Patrones al rescate…
Duplicar datos
Cuando trabajas modelando una base de datos relacional, lo normal es que evites duplicar datos en diferentes tablas... bueno, hasta que las cosas no empiezan a ir bien de rendimiento y te planteas trampear tu modelo (como decía Groucho Marx: Éstos son mis principios, y si no le gustan, tengo otros).
En MongoDB SI nos podemos plantear duplicar datos en el caso de que esto signifique obtener consultas más simples y rápidas ¿Siempre? No... aquí tenemos que sopesar cuántas lecturas vamos a realizar vs cuántas escrituras y cuanto nos va a costar hacer una actualización de datos.
Un ejemplo sencillo: tenemos una colección de libros y otra de autores (un libro puede tener múltiples autores, y un autor puede haber escrito muchos libros), cuando cargamos la ficha del libro en nuestra tienda online queremos mostrar el libro así como el nombre de los autores, ¿Por qué no, en vez de ponernos a tirar joins, no almacenamos el id, y el nombre de los autores en el documento del libro (duplicando esos datos en un array de autores dentro del documento de libro)?, siguiendo esta aproximación, comparemos:
Como lo modelaríamos en relacional

Qué podríamos hacer con MongoDB

Cuando carguemos la ficha del libro directamente cargamos de una tacada la info que necesitamos en una sola consulta.
El nombre de un autor es complicado que cambie (salvo que hayamos cometido un error), en ese caso, podemos pagar la penalización de tener que actualizar un nombre de autor en varios libros a cambio de que la ficha de un libro cargue como un rayo.
Subset & Outlier & Computed pattern
Ahora llegamos al gran dilema, ¿Qué pasa si en la ficha de un libro de mi web de ecommerce quiero cargar las reseñas de un libro?... aquí lo primero que podemos pensar es: genial voy a embeber la reseñas dentro de la colección de libros ¿Correcto? Mmmm...nos podemos encontrar que un libro famoso podría tener perfectamente 100.000 reseñas y entonces, además de llenar el Working Set de basura (pocas personas van a a leer las cien mil reseñas de una sentada), podemos llegar a límite fatídico de los 16Mb por documento.
¿Te has fijado en lo que hace Amazon? Por un lado te enseña las últimas 10 reseñas (o las 10 más relevantes), y por otro la media de votaciones, ¿Cómo podemos hacer algo así con Mongo?
Por un lado tenemos una colección de libros y otra de reseñas, peeeerooooo... en el documento de libros duplicamos las últimas 10 reseñas (de esta manera en una consulta cargamos los datos necesarios para mostrar en la página de ficha del libro), es decir aplicamos el subset pattern.
Por otro lado, cuando mostramos la media de puntuaciones que ha recibido el libro, en vez de tirar una consulta cada vez que un usuario carga un libro, podemos tener un campo precalculado, en este caso aplicamos el computed pattern en la misma colección del libro: almacenamos la media de todas las puntuaciones ¿Cuando se actualiza este valor? Podemos optar por dos opciones, o bien cuando un usuario introduce una nueva reseña (se realiza una escritura y se lanza la consulta para calcular la nueva media de libros y actualizar el campo calculado), o bien realizar esta operación en un proceso batch cada X horas / días (no hace falta que demos la media de puntuación en tiempo real).
Por último, si resulta que la mayoría de entradas de una colección tiene un tamaño de documento pequeño y sólo son una pocas las que tienen una burrada de datos y se pasan de los 16 Mb, te puedes plantear aplicar el outlier pattern y mover esos documentos a otra colección, pero ojo que este patrón no viene gratis, ¿Donde pagas el pato? En que para ciertos escenarios vas a tener que tirar dos consultas, o añadir un paso más a tu consulta agregada.
Volvemos al ejemplo inicial del pedido
Ahora que hemos aterrizado estos conceptos, podemos volver al listado de pedidos, imagínate que tenemos este escenario:
Tenemos miles de pedidos.
Tenemos miles de usuarios.
Mostramos un grid con una información resumida de los pedidos (y decidimos mostrar un montón de entradas en ese grid).
Cuando el usuario pincha en un pedido en concreto ya se le muestra la información detallada del pedido.
Para este escenario ¿Qué pasa si tenemos cabecera y detalle de pedido en una misma colección? Que iríamos llenando el Working Set de documentos que contienen más información de la cuenta, ya que sólo queremos mostrar el sumario de un pedido en ese listado mogollónico de sumarios.
¿Qué podemos hacer?
Una opción sería volver a la aproximación inicial de tener la cabecera del pedido y el detalle separado, de esta manera:
Puedo lanzar una consulta para las cabeceras.
Cuando decido cargar un detalle, puedo optar por mantener la cabecera en memoria de la aplicación y cargar sólo el detalle.
También podría crear una colección en la que sólo muestro los datos que se están viendo en el grid de resultados, de esta manera:
Tengo en el Working set justo la información que se usa en el grid de detalle.
Cuando ya pincho en cargar en un pedido con una consulta simple cargo cabecera y detalle (que si están en una misma colección).
¿Quiere esto decir que debo de seguir esta aproximación siempre? La respuesta es NO, y aquí es donde está la diferencia con el modelado relacional, tienes que estudiar que escenario estás manejando, veamos:
¿Cuanto pesa tu base de datos?_ Igual estamos hablando de menos de 100 Mb, y cuentas con varios gigas de _Working Set_ en memoria (mejor tener un modelado menos complejo y consultas más sencillas).
También puede que muestres tu lista de pedidos paginada, y te puede traer cuenta tener esos pedido precargados en memoria (a fin de cuentas la linea de detalles será un puñado de Kilobytes, y hay muchas posibilidades de que quieras cargar el detalle de uno de los pedidos que se está mostrando).
Vale, pero y si resulta que mi base de datos va creciendo, ¿No puede ser que más adelante sea demasiado tarde aplicar un cambio de calado en la estructura? Las bases de datos documentales no son tan rígidas como las relacionales, puedes hacer un cambio en batch cuando te haga falta, si te ayudas del versioning pattern puede que no te haga falta ni parar el servicio para realizar la actualización (ojo, puede implicar un trabajo de migración, no es algo gratuito).
Un caso más complejo
Hablar de estos temas, tomando como ejemplo un caso simple en el que discutimos si unificar un maestro / detalle está bien para entender los conceptos, pero lo ideal es que nos metamos más en harina, veamos el siguiente caso: imaginemos que queremos modelar la carta online de un restaurante, para ello vamos a partir del siguiente escenario básico, tenemos:
Una serie de categorías (entrantes, platos principales, postres, bebidas...).
Una serie de platos (que pertenecen a una categoría).
Cada plato puede tener tipos de raciones (tapa/media/ración, caña/tubo/maceta/jarra, copa/botella), y además cada definición de ración es propia de cada restaurante (te puedes encontrar que el concepto de tapa es distinto de una ciudad a otra).
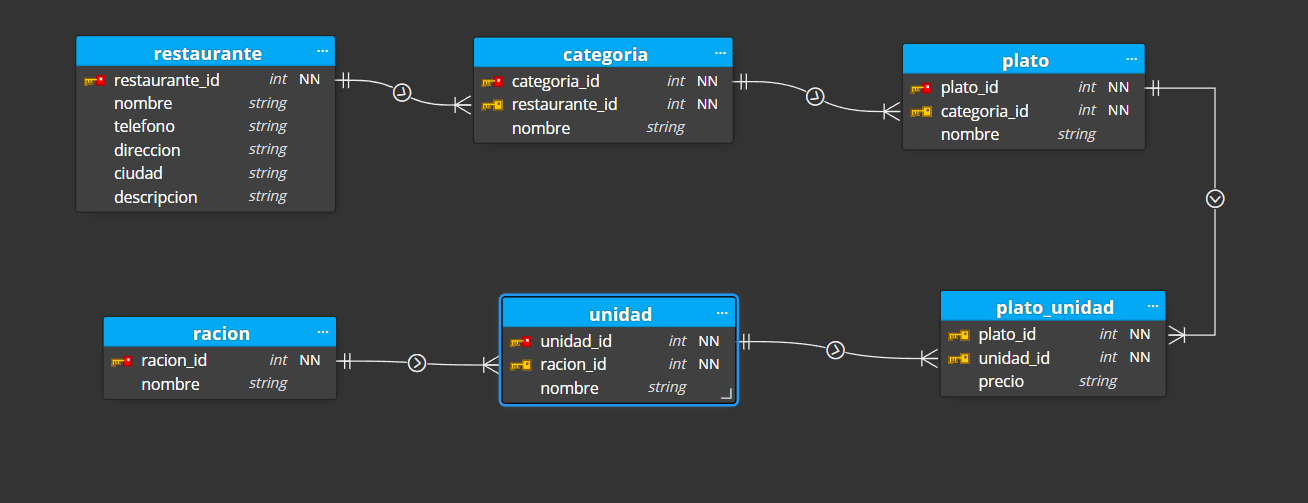
Como podríamos modelar esto en relacional:
Tablas:
Tenemos una tabla de restaurante.
Tenemos una tabla de categorías.
Tenemos una tabla de platos.
Tenemos una tabla de raciones y otra de unidades de ración.
Relaciones:
Un restaurante tiene muchas categorías.
Una categoría tiene muchos platos.
Una ración tiene muchas unidades de ración.
Un plato tiene muchas unidades de ración.- (...)
El modelado quedaría tal que así:
¿Y si quisiéramos leer carta de un restaurante? Si lo intentamos hacer en una sóla consulta, podríamos intentar algo tal que así(*):
SELECT *
FROM restaurante R
INNER JOIN categoria C
ON R.restaurante_id = C.restaurante_id
INNER JOIN plato P
ON P.categoria_id = C.categoria_id
INNER JOIN plato_unidad PU
ON PU.plato_id = P.plato_id
INNER JOIN unidad U
ON U.unidad_id = PU.unidad_id
INNER JOIN racion RC
ON RC.racion_id = U.racion_id
WHERE R.restaurante_id = 2
Y no estamos hablando de incluir otras posibles entidades, como alérgenos o guardar un borrador de cartas :)...
(*) De cara a simplificar la consulta hemos usado el comodín asterísco, también podríamos mirar de partirlo en varias consultas.
Vamos ahora a ver como lo podríamos modelar en MongoDB.
La colección de restaurantes.
Y esta colección tiene embebido:
Una definición de raciones para ese restaurante.
Un array de objetos complejos que contienen categorías con su array de platos, y los platos con su definición de ración.
Para hacernos una idea, lo podemos modelar en TypeScript con este código:
interface TipoUnidad {
_id: ObjectId;
nombre: string;
precio: string;
}
interface DefinicionRacion {
_id: ObjectId;
nombre: string;
unidades: TipoUnidad[];
}
interface Plato {
_id: ObjectId;
nombre: string;
raciones: DefinicionRacion;
}
interface Categoria {
_id: ObjectId;
nombre: string;
platos: Plato[];
}
interface Unidad {
_id: ObjectId;
nombre: string;
}
interface Racion {
_id: ObjectId;
nombre: string;
unidades: Unidad[];
}
interface Restaurante {
_id: ObjectId;
nombre: string;
telefono: string;
direccion: string;
ciudad: string;
descripcion: string;
raciones: Racion[];
menu: Categoria[];
}Y un ejemplo con datos:
const restaurante: Restaurante = {
_id: new ObjectId("638659f8bd883f830a1ed83d"),
nombre: "El restaurante",
telefono: "123456789",
direccion: "Calle restaurante 123",
ciudad: "Málaga",
descripcion: "El mejor restaurante de Málaga",
raciones: [
{
_id: new ObjectId("63865a191d593c7faed66bf8"),
nombre: "Ración",
unidades: [
{
_id: new ObjectId("63865a2f2bca81ba0eef55aa"),
nombre: "media ración",
},
],
},
],
menu: [
{
_id: new ObjectId("63865a79d36ceb87efbce74f"),
nombre: "Entrantes",
platos: [
{
_id: new ObjectId("63865a88a93cea2840eadde2"),
nombre: "Ensalada",
raciones: {
_id: new ObjectId("63865a191d593c7faed66bf8"),
nombre: "Ración",
unidades: [
{
_id: new ObjectId("63865a2f2bca81ba0eef55aa"),
nombre: "Unidad",
precio: "1.50",
},
],
},
},
],
},
],
};
Ya que lo tenemos claro veamos como quedaría el modelo documental:

¿Cómo sería la consulta para leer los datos de un restaurante?
db.restaurante.findOne({_id: new ObjectId("638659f8bd883f830a1ed83d")});
Si te fijas cargar la carta de un restaurante se convierte en un juego de niños, y el Working Set lo tenemos bastante optimizado (en un momento dado, aquí podríamos plantearnos hacer como en el caso de anterior de lista de pedidos, tener una colección con el sumario del restaurante y otra con la info y carta completa del restaurante).
Conclusiones
Espero que en este artículo hayas encontrado algunas pautas que te sean de ayuda cuando estés dudando si embeber o crear una relación entre tablas, como resumen:
Piensa en el volumen de datos que vas a manejar.
Plantéate como se van a consultar los datos en tu aplicación.
Acuérdate del límite físico de un documento.
Decide si relación / embeber o aplicar un patrón como el subset pattern.
Como resumen del post aquí tienes este árbol de decisiones:
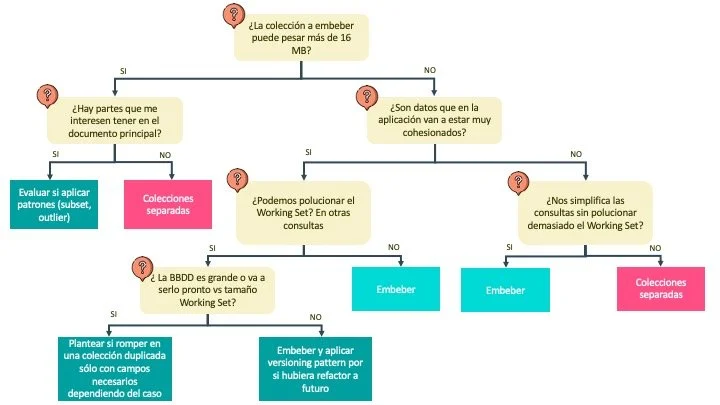
De propina...
Otro tema muy importante a tener en cuenta para tener un buen rendimiento conforme tu base de datos va creciendo es la creación de indices para optimizar las consultas más críticas, en esta mini serie de Lemoncode Tv puedes encontrar unos video tutoriales (con post incluido) para poder iniciarte.
¿Front, Dev o Back?
Si tienes ganas de ponerte al día ¿Te apuntas a alguno de nuestros Masters Online o Bootcamps?